So I read this thread:
And got the impression that many people don’t understand how (and if) Gig Performer can use multiple cores.
I wasn’t understanding it either. In my experience, GP performs really well, but since this seems to be a topic of interest, so let’s demystify it! I did some research on the forum and came up with some assumptions and further questions that I’m interested to hear your opinion about (especially @djogon and @dhj)
Assumption 1: Only the plugins in the currently active rackspace consume CPU cycles
Was confirmed here:
Assumption 2: Gig Performer launches all plugins in the same thread
All the blocks in connection view (= plugins) are launched in the same thread by GP. As a single thread cannot be run on multiple cores at once, you get a CPU-intensive thread which cannot use more than a single core.
Assumption 3: Plugins can launch their own threads to make use of multiple cores
So plugins can make use of multiple cores on their own, independent of GP. I checked for a few popular virtual instruments, if they actually do that:
- Kontakt

- Reaktor
 Source
Source - Diva
Screenshot of main window

- Pianoteq (limited to two cores) Source
- Omnisphere Source (despite being a known CPU hog
 )
)
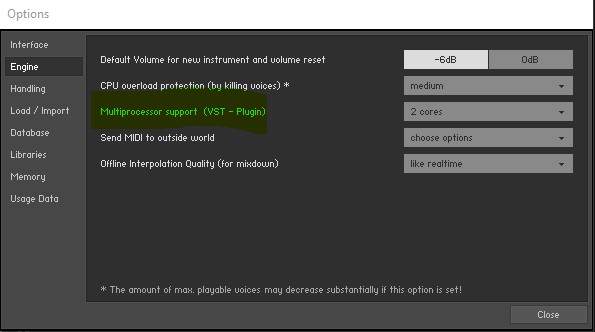
So that means, plugins like Kontakt can easily distribute their loads over multiple cores and do not stress the “main GP audio thread” very much, whereas in Omnisphere, whether you’re using multiple sounds in a single instance or multiple instances with one sound each, they all run in a single thread.
Assumption 4: GP could run different plugins in different threads
I understand @djogon’s argument concerning parallel processing:
But I have counter-argument: All “classic” DAWs I checked (Ableton, Logic + Mainstage, Reason (with some troubles), Reaper, Studio One) distribute plugins over multiple (DAW-owned) thread. Although the plugins of a single channel cannot be spread across multiple threads, they seem to be able to distribute the plugins on a per-channel-basis.
The equivalent of two independent channels in a classic DAW in GP would be the following routing:
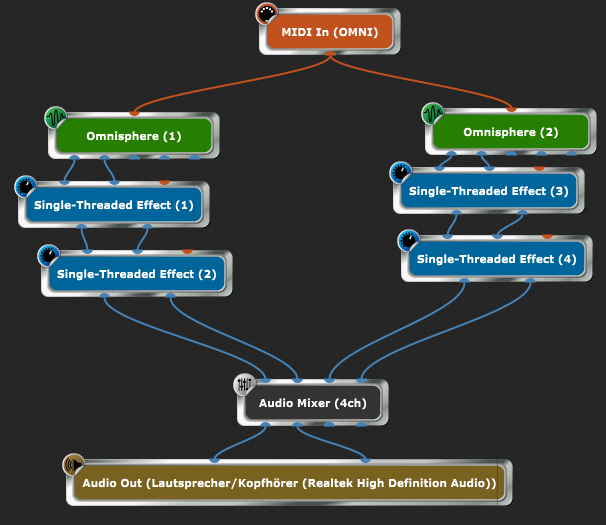
Currently, all the processing here would need to have to be done in a single thread, right?
What are the reasons that Gig Performer can not assign the left and right path to different threads?
Is this a limitation given by the principles of GP? Or by the underlying framework? Or would it be possible, but just not implemented yet?
Looking forward to your thoughts on this! ![]()

